The American legal system sets the minimum age of drinking alcohol at 21 years. However, this law presents a problem for the majority of undergraduate college students who are younger than 21 years of age and eager to drink. Many of these students circumvent this problem by using fake identification in order to gain access to alcohol. As undergraduate students of Columbia University, we ask the question, "What proportion of the freshman class own fake IDs?" Specifically, we focused on the two exclusively freshmen dorms on campus that house the majority of the freshman class: John Jay Hall and Carman Hall. So the question we are seeking to answer becomes "What proportion of the freshman class living in John Jay and Carman halls own fake IDs?"
For our data collection, we randomly chose a sample size of 60 students using Table B in the back of the textbook. However, since John Jay and Carman Halls do not house equal numbers of students, we opted to utilize a multistage sampling design by which we stratified the freshmen population by dormitory, and then stratified each dormitory into blocks according to floors. Since our question of interest addresses the ownership of fake IDs, which are illegal, we predicted that many students may feel uncomfortable answering this question; therefore, we utilized a Randomized Response Technique to provide adequate anonymity so that students feel comfortable telling the truth.
Prior to beginning our data collection, we carefully considered the wording of the sensitive question so as to diminish bias and the likelihood of non-response.
Our initial plan was to complete our data collection within the span of two days. However, upon implementation of this initial protocol, we realized that two days was an insufficient amount of time to complete data collection, and so we extended the data collection period to four days, in which we were able to gather all of our data.
The population of our study consisted of the two exclusively first-year undergraduate student dormitories on the Columbia University campus. These two dormitories are Carman Hall and John Jay Hall. According to the Columbia University's University Residence Hall (URH) website, the population of John Jay dormitory is 459 first-year students, and the population of Carman dormitory is 572 first-year students. We summed up these two populations, giving the overall population of 1031 first-year students to comprise our entire population.
For our sample size to appropriately represent this population, we decided that a sample size of 60 students would be a feasible and sufficient number. Since the total number of students living in John Jay versus Carman is not equal, there are unequal probabilities for individuals from each of these dormitories that would not be accounted for if we just used the same Simple Random Sample (SRS) size for each. Therefore, we decided to use stratified sampling, first dividing the population into two separate groups of similar individuals and then choosing a separate SRS in each stratum, and finally combining the two SRSs to form the full sample. We designated each dormitory as a separate stratum based on the fact that they are two different dormitories housing two different numbers of total students in order to establish a Simple Random Sample size proportional to strata size for each dormitory. However, since each dormitory has several floors, we decided to divide each dorm into smaller units of floors; each floor is thus a "block." Since we are stratifying the two strata into blocks, each of which represent one floor, this is considered a multistage sampling design.
To determine the number of students from each dormitory that should be chosen to accurately represent the overall population according to the correct proportions, we first divided the number of students in one dormitory by the overall population, and then multiplied this number by the total sample size that we desired:
To determine the number of people that should be in each stratum:
John Jay: [(459 John Jay Students)/(1031 Overall Number of Students)] * (60 Desired Sample Size) = 27 John Jay Students
Carman: [(572 Carman Students)/(1031 Overall Number of Students)] * (60 Desired Sample Size) = 33 Carman Students
Within John Jay, there are 9 floors with equal numbers of students. Thus, to determine the number of students in each block or floor, we divided (27 John Jay Students to be Sampled) / (9 Floors in John Jay) = 3 Students/Block or Floor in John Jay.
Within Carman, there are 11 floors with equal numbers of students. Thus, to determine the number of students in each block or floor, we divided (33 Carman Students to be Sampled) / (11 Floors in Carman) = 3 Students/Block or Floor in Carman.
In order to randomly choose the 3 students per block, we made a list of all the room numbers for each block or floor and then assigned each of them a numerical label. Then, using the Random Digits Table in the textbook (Table B), we randomly attained 3 room numbers to comprise the groups of three specific students in the blocks.
After this initial preparation had been complete, in order to successfully obtain data from all the specified students from our randomization, we planned to visit the two dormitories over the course of two days at various times of the day during which we assumed students to be most likely in their rooms: Thursday, February 19, 2004, Friday, February 20, 2004, approximately between 6PM to 10PM each day.
When we approached the students, we first explained that they were randomly chosen to participate in our study for a Statistics class. We emphasized that their participation in our study would be completely anonymous in order to decrease the chances of lying and/or non-response from the chosen students. To further increase the students' likelihood to agree to participate, we also emphasized that their time commitment in our survey would be minimal: specifically, that it would only take 1-2 minutes to administer the entire survey. Because our in-person survey was described in the manner we discussed above, we were fortunate to attain 100% participation from every selected student in our sample size.
Since the wording of questions in the survey is the most important influence on the answers given to a sample survey and can tremendously influence the subjects' replies to the question, we carefully considered the appropriate construction and wording of our question prior to implementing the study so as to avoid confusing questions liable of introducing strong bias in the response. We decided to use the term "Fake IDs" instead of "False Identification" because "False Identification" is a term that entities such as the police or governmental authorities would use to incriminate individuals, so use of this term would likely cause response bias in the subjects since they might be intimidated by the legality of the term and therefore may not answer the question truthfully. The term "Fake IDs," on the other hand, is more colloquial and is the term most commonly used among college students; therefore, our subjects would likely feel more comfortable answering a question that uses a more familiar term. Similarly, we also weighed the pros and cons of using the verbs "possess" versus "own." We felt that the verb "possess" holds too many negative connotations, since it is often used in reference to various illegal activities, such as "the possession of drugs, alcohol, or handguns." Therefore, we chose to use the verb "own," which is a less intimidating, more objective term. Taking these factors into consideration, we formulated the question, "Do you own a fake ID?" However, we felt that this question seemed too abrupt and interrogative in nature. Thus, we decided to add the modifier "currently" into the survey question to lend more focus to the question itself as well as mitigating the tone of the question to soften its delivery. And thus, we arrived at the optimal wording of the question: "Do you currently own a fake ID?"
Since our topic is a sensitive issue, some people may feel uncomfortable answering our observational study truthfully. This could be a potential problem in our data collection protocol. Therefore, we decided to use the Randomized Response Technique in order to account for possible lying. Once the students agreed to participate in our study, we asked them to flip a quarter that we provided. Prior to their flipping the quarter, we explained to them the following conditions: if their flip resulted in a heads, they should answer the question: "Do you currently own a fake ID?" and if their flip resulted in a tails, they should answer the question: "Are you currently a Columbia University student?" Subsequently, we requested that they truthfully answer the appropriate question based on the result of their coin flip but that they do not tell us, the surveyors, the result of their coin flip and thus the particular question they are answering. By employing this randomized response technique, we minimize the likelihood of lying, because if we were to simply ask the sensitive question "Do you currently own a fake ID?", many of the subjects who do own fake Ids may not feel comfortable replying "Yes" and therefore may lie and submit a "No" reply instead, which would affect the validity of our data. But since we used the randomized response technique in which there is a fifty percent chance that they would be able to answer the non-sensitive question, "Are you currently a Columbia University student?", to which all of the replies would be guaranteed "Yes," the subject would not feel the need to lie because if their answer were "Yes," no one would know whether the question they are answering is the sensitive one or the non-sensitive one. Although we do not know whether each specific individual owns a fake ID, we are not interested in this information but are rather interested in obtaining an honest overall estimate for the whole population with regards to owning a fake ID. Although this randomized response technique protects against lying, there is a possibility that the subject would still lie if they believed that we, the surveyors, saw the result of their coin flip. Therefore, to avoid this difficulty, we turned to face the opposite direction while the subjects flipped the coin to ensure that we did not see the result of the coin toss, but more importantly, that the subjects know that there were no chances that we saw the result.
But despite our careful planning prior to the data collection, we did experience some unexpected difficulties. We had initially allotted two days to collect the data completely, which proved insufficient to attaining all the data. Many of the subjects were absent from their rooms, probably because it was during dinnertime. However, since we allotted ourselves sufficient number of days to complete the project, we extended our data-collecting time frame from two to four days and were able to successfully gather all the necessary data by revisiting the dorms that we were unable to contact initially.
As described previously, our sample size consisted of 60 subjects. Of these subjects, 51 answered "Yes," and 9 answered "No" to our question. However, since we used the Randomized Response Technique to gather our data, these numbers do not accurately represent the results for our sensitive study question but rather represent the results for both our sensitive study question ("Do you currently own a fake ID?") and our non-sensitive or harmless question (Are you currently a Columbia student?"). Therefore, in order to extrapolate the useful data, we need to use the rules of probability. We shall explain our calculations in the following description as well as with a tree diagram.
Our subjects were asked to flip a coin. If their result was Heads, they answered our sensitive study question, and if their result was Tails, they answered the harmless question. The probability of receiving a Heads is ˝ or 0.5, and that of receiving a Tails is also ˝ or 0.5. However, we are only interested in the results from the Heads question; therefore, the Tails question was intentionally designed to elicit 100% "Yes" responses (since everyone we asked is a Columbia student) so that we can factor out a certain proportion of the responses. Since we had 60 subjects, and the probability of receiving a Tails is 0.5, this suggests that approximately 30 people answered the Tails question, and 30 answered the Heads question. Since we know that the 30 people who answered the Tails question must all have answered "Yes," we subtracted this number from the overall number of "Yes" responses. Therefore, we can deduce that the number of people who actually own a fake ID is (51-30) = 21/30. In addition, the number of people who do not own fake Ids is 9/30.
These results can be shown statistically in a tree diagram.
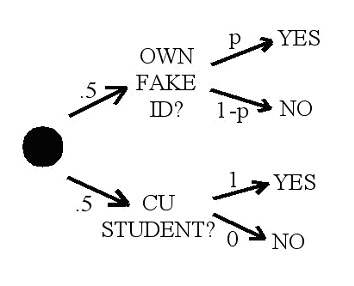
From the probabilities within the tree diagram, we are able to obtain the equation that represents the total proportion people answering "Yes." Since there are two "Yes" branches on the tree diagram, we just calculated the probability of "Yes" from each branch separately, and then added them up to attain the total probability of "Yes" answers. The probability of "Yes" answers is P*0.5 on the top branch, and the probability of "Yes" answers is 1*0.5 on the bottom branch. Thus, the expression (˝)P + (˝) equals the total probability of "Yes" responses. Within this equation, P represents the proportion of people who currently own fake IDs, which is the variable in which we are interested. When this above expression is set equal to the proportion of total numerical "Yes" answers, P, the proportion of people who currently own fake IDs, can be solved for:
(˝)P + (˝) = 51/60
P = 0.7
1-P = 0.3
Therefore, the number of people out of our whole sample size who own fake IDs can be determined by multiplying P by the total number of people who answered the fake ID question (0.5*60 = 30):
P*0.5*60 = 0.7*0.5*60 = 21 People who currently own fake IDs Similarly, the number of people who answered "No" can be calculated:
(1-P)*0.5*60 = 0.3*0.5*60 = 9 People who currently do not own fake IDs
Of our sample, 70% (21 students) owned fake IDs, and 30% (9 students) did not own fake IDs.
a) After conducting our survey, we learned many statistical concepts. For example, we learned the importance of choosing the appropriate wording when constructing our survey questions. The manner in which a question is put forth has the greatest influence on how a subject responds, especially when it is a sensitive question that is being asked. Thus, by choosing the correct wording of a question, one can eliminate the largest source of bias from a statistical study. We also learned about the usefulness of the Randomized Response technique. Since we asked a sensitive question, simply asking our subjects this question in a straightforward fashion may make them uncomfortable, and thus they may possibly lie in their response. Thus, using the Randomized Response technique, where the subject feels that they are not revealing any sensitive information about themselves, we as the surveyors can still obtain accurate information from subjects even if it is obtained in an indirect manner. This, in fact, leads to another concept we have learned: individual outcomes are trivial, compared to what can be assumed about the sample as a whole, and thus the population as well.
b) We feel that the methods that we employed were the correct ones in order to obtain an accurate sample of the overall population, and thus the question that we posed ("What proportion of the freshman class living in John Jay and Carman halls own fake IDs?") can be answered by our data. We utilized various strategies (such as randomization, word choice, etc) that have already been described in the previous sections in order to ensure that we obtained accurate and unbiased data. The only thing that we would change if we wanted to make significant assumptions about our population is our sample size. Because of time constraints, we were limited in our ability to obtain a larger sample; our sample represented only 3% of our total population. A small sample is prone to more fallibility than a larger one, as stated in the law of large numbers. Thus, in order to make assumptions about our population, it would be more statistically accurate if the sample size was larger, about 10% or larger.
c) The main source of bias in our data is the fact that we have a relatively small sample size, as discussed in Part B. The smaller the sample size, the more it is susceptible to variation and chance phenomena. Another large source of bias in many studies is non-response. Luckily, we did not have any cases of non-response, and thus this type of bias did not affect our data.
d) From the data that we gathered and our initial choice to stratify the data according to dormitory, we discovered what could potentially be significant differences in responses to the question we posed between the two dorms. Thus, we could potentially use these data for project 2. However, the question we pose ("What proportion of the freshman class living in John Jay and Carman halls own fake IDs?) would be modified because our question in the first project does not address the differences between the two dorms. Therefore, the question we would be asking in the next project would be restructured more along the lines of ("How does ownership of fake IDs vary depending on the specific dormitory freshmen live in?"). To analyze this new question, we would find the individual probabilities of owing a fake ID for each dorm instead of calculating the probability of the freshmen as a whole. We could then analyze these probabilities in order to make assumptions about the populations of John Jay and Carman.